|
 Idea
for the Project Idea
for the Project
The idea for transcribing the list of veterans from the
Cuban War of Independence into a public web based resource was initially
conceived by Maria de la Torre.
We checked the copyright status and found that there should
be no legal obstacles to doing such a transcription. Although at first
we were a bit skeptical that we could ever finish such a large project
(the number of names to be transcribed numbered 69,770), we decided to
give it a try.
Planning
the Project
We first made a number of experiments to determine if it was possible
to scan the information directly into computer readable format using OCR
software. This proved to be not feasible due to the very poor quality
of the available text, and because of the type and small size of the font
used (scanning did prove successful later when transcribing the death
notices which were printed using a larger type).
Briefly we considered the possiblity of publishing the individual pages
as image reproductions. This idea was also found to be not practical.
In order to reproduce the small type, high resoultion images were required,
which in turn required large file sizes. The large number of pages (1004
pages in the soldiers listing plus 263 pages in the death listings) would
have required additional storage to be leased on a monthly basis from
the web service provider, adding to the costs of hosting CubaGenWeb.
This method would also have had the very serious disadvantage of not being
searchable on a name-by-name basis.
The conclusion we quickly reached that we would have to transcribe the
data manually. This involved a) developing a method to transcribe the
data that would be easy for volunteers to use and b) developing a method
for posting and retrieving the data on the web that would be user friendly
and would impose minimal requirements on the web service provider hosting CubaGenWeb.
A search was done for commercial web-based search engine software having
the desired characteristics. Fortunately such software was quickly found,
although it imposed some limitations on the number of records per file
and number of fields per record. These limitations were felt to be not
too severe. The software was procured, the user interface was customized,
and tests were made to verify operation and how best to input the data.
A format for the data was then designed which closely followed the order
of data in each entry in the original book and added the regiment information
to each entry so that it would be retained after sorting. Codes were assigned
to each regiment to minimize the typing requirements and to provide uniform
nomenclature in all the entries.
The final record format selected retained all the information in the
original entry with the exception of the volume, folio and page number
of the original document in the Cuban National Archives and remarks appearing
after some of the entries. It was felt that the location of the original
records would be of interest only to someone with physical access to the
Archives. Such an individual could easily find the information by searching
the index while at the Archives, or by searching a copy of the Roloff
book or a microfilm copy of the book.
Although a few of the remarks in the original entries were of historical
interest, indicating, for example, that a certain individual worked at
a "taller" (machine shop),or was a "proveedor" (supplier),
most remarks consisted simply of the statement "grado por aclarar"
(rank pending to be verified). It was felt that these remarks would add
significanlty to the transcription effort while they were of limited genealogical
significance without the benefit of any subsequent verification. In the
end it was decided to omit the remarks from the transcription.
A list of instructions was then prepared indicating how to enter the
data at home into a spreadsheet or a word processor and how to resolve
the most common questions and conflicts, as well as how to transmit the
data back to us. These instructions were updated as a result of the questions
received from the first transcribers (see the entry on the left menu titled
"Instructions to Transcribers").
At the receiving end, we also prepared software to pre-process the received
spreadsheet data into the format expected by the data base engine and
also to correct common errors such as converting all dates to use Spanish
abbreviations, removing any commas in the entries, etc. We also developed
reporting software to check for errors, duplicates or gaps in the sequence
numbers of the entries and to keep track of the progress of the transcription
(see the entry on the left menu titled "Project Status" for
the most current example).
Finally it was time to enlist the help of volunteers to actually transcribe
the data.
Executing
the Project
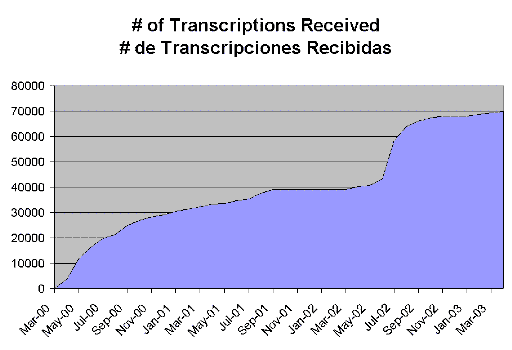
The call for volunteers was posted to the CUBA-L list on 3 April 2000, with the first test transcriptions from the volunteers
received on 11 April 2000. The transcriptions kept coming in steadily
until September 2001, when they almost completely stopped a little over
half way done (see Figure below). This was likely due to other demands
for time on the volunteers.
Nothing much happened for the next 9 months until the Miami
Cuban Genealogy Club's Genealogy Conference in May 2002. At this conference
we learned that there was still a great level of interest in finishing
the project and we also learned that one of the Club members had been
successful in obtaining a copy of the original book on eBay. We followed
suit and were lucky enought to also obtain a copy. Having the original
in our hands allowed us to make high quality copies of the pages to facilitate
transcription (the legibility of the copies had always been a problem).
It also made it possible for us to respond almost immediately to the requests
of volunteers so as not to loose interest or project momentum.
A new call for volunteers went out via the CUBA-L list. This latest crop of volunteers (which included some of the original
ones) was able to rapidly complete most of the project. Again, though,
the rate of transcriptions tapered off after a few months and it looked
like it would take forever to finish. Once again, a handful of volunteers
was solicited for the final push. The project was finally completed on
13 April 2003, three years after it was started.
 List of volunteers from whom we received transcriptions: List of volunteers from whom we received transcriptions:
In the end, a total of 34 volunteer transcribers participated in the
project, which took 3 years. As to be expected, due to differences in
typing ability and available free time, there was a large variation in
the number of names transcribed by each individual.
We specially thank Maria de la Torre,
who produced and distributed the copies to be transcribed during the
first two years of the project. We are all grateful to and thank the
following volunteer transcribers that made the project possible:
| Transcriber |
# of names transcribed
(as of
03-May-2015
) |
| C. Victor Hernandez |
6704 |
| Ed Elizondo |
6495 |
| Matt Perez |
5735 |
| Norma Cabrera |
5106 |
| Martha Ibanez Zervoudakis |
4381 |
| Edward E. Baez |
4175 |
| Mary Ann Garza |
3919 |
| Mariela Fernandez |
3884 |
| Donna Suarez |
3743 |
| Susan Muzio Conner |
3556 |
| Raclare Kanal |
2660 |
| Andres Villalon |
2216 |
| Jose A. Tavel |
2033 |
| John Rogers |
1509 |
| Cindy Braman |
1469 |
| Stephen Barranco |
1434 |
| Donna Costa |
908 |
| Maria de la Torre |
817 |
| Georgina McWherter |
812 |
| Adriana Power |
780 |
| Cecilia Vaillant-Yanes |
777 |
| Jennifer Becker-Diaz |
768 |
| Alan Perry |
715 |
| Patricia Pulles |
690 |
| Ben Diaz, Jr. |
690 |
| Vicente Sanchez |
651 |
| Nancy Padron |
623 |
| Luly Del Pino |
601 |
| Cheryl Sanders-Sivers |
436 |
| Eddie Ramos |
410 |
| Jorge Gregorisch |
369 |
| Nidia Gonzalez |
348 |
| Agueda Hernandez |
317 |
| Hilda Pomares |
39 |
Thank You!
Log
of Files Received
Here is a detailed log of all the files received:

|

